
MJay
[CSE 530]- 시험 공부 본문
Computer Architecture 공부

Throughput 이다. PipeLining으로 인해 할수있는 양이 늘어났다.
Cache - Temporal, Spatial Locality

2 * 10 ^ 9 을 역수로 하면 된다.
G -> 2 ^ 9 이였나. 그냥 외우자 일단

Cache는 보면 physical address 랑 관련있는 듯
Number of sets -> 64kB / 2 * 32 = 2 ^ 10 10 bits 이다. 즉 Index가 10개라는 걸 뜻한다.
2 ^ 5 = 5 bits are block offset -> offset은 아마 set 안에서 몇개의 블락이 있는 거니까 32B Cache -> 2 ^ 5 을 뜻하는 거 같다.
Tag Overhead - 17 bits * 2 ^ 10 * 2
Tag Overhead 는 Number of Sets * 17 * 2 -> Tag bit * Number of Sets * Number of Ways

2 * 8 의 square 취하면 된다.
Latency는 곱하면 되는거 같다.

CPI, Cycle Time, Number of Instructions

Instruction 이 3배로 많아지면 느려지니까 반대로 된다고 생각하면 될듯하다.
cycles per instruction (aka clock cycles per instruction, clocks per instruction, or CPI) is one aspect of a processor's performance:

이것도 빠른 부분 Speedup 에 해당하는 부분이 40%이고 나머지는 1- 40% = 60%
이렇게 된다. 뭐 그런거구나

Arrays - Due to Spatial Locality , Cache는 Block 개념이니까 이걸 설명을 어떻게 해야할까
As a concrete example, the sequence of load addresses for a sequential array access is nice and predictable. For example, 1000, 1016, 1032, 1064, etc.
For a linked list it will look like: 1000, 3048, 5040, 7888, etc. Very hard to predict the next address.

0x 는 hexadecimal -
0xbeef -> 16 bit 가 맞다 b 가 4개이니까
5 7 5 로 나눠져 있고
오른쪽에서부터 읽으면 된다.
자세한 정답


식으로 한 거는 local이고
global은 그전에 겹치는 거니까 l1 - miss rate도 곱해주면 된다.
0.05 * ½ 를 해주면 된다.


load / store은 data cache 쪽이다.
IDeal + 5 * (10 + 0.4 *100) + 0.4*0.15(10+0.4*100)


For ease of programming and security, giving the illusion of infinite memory

Main memory는 physical address를 뜻한다.
2 ^ 34이다.
34 bits (16Gb)에서 12 bits (4kB)를 뺀 거가 -> Physical Page Numbers이고 34-12 = 22 bits 이다.
64 - 12 = 54 가 Virtual Page Numbers이다. 54 page

Translation Lookaside Buffer
For fast translation from virtual memory to physical memory

TLB -> Page Walk -> L1 -> L2 ->
2 -> 6 -> 7 -> 5 -> 3 -> 8-> 4 -> 1





hierarchy로 충분함



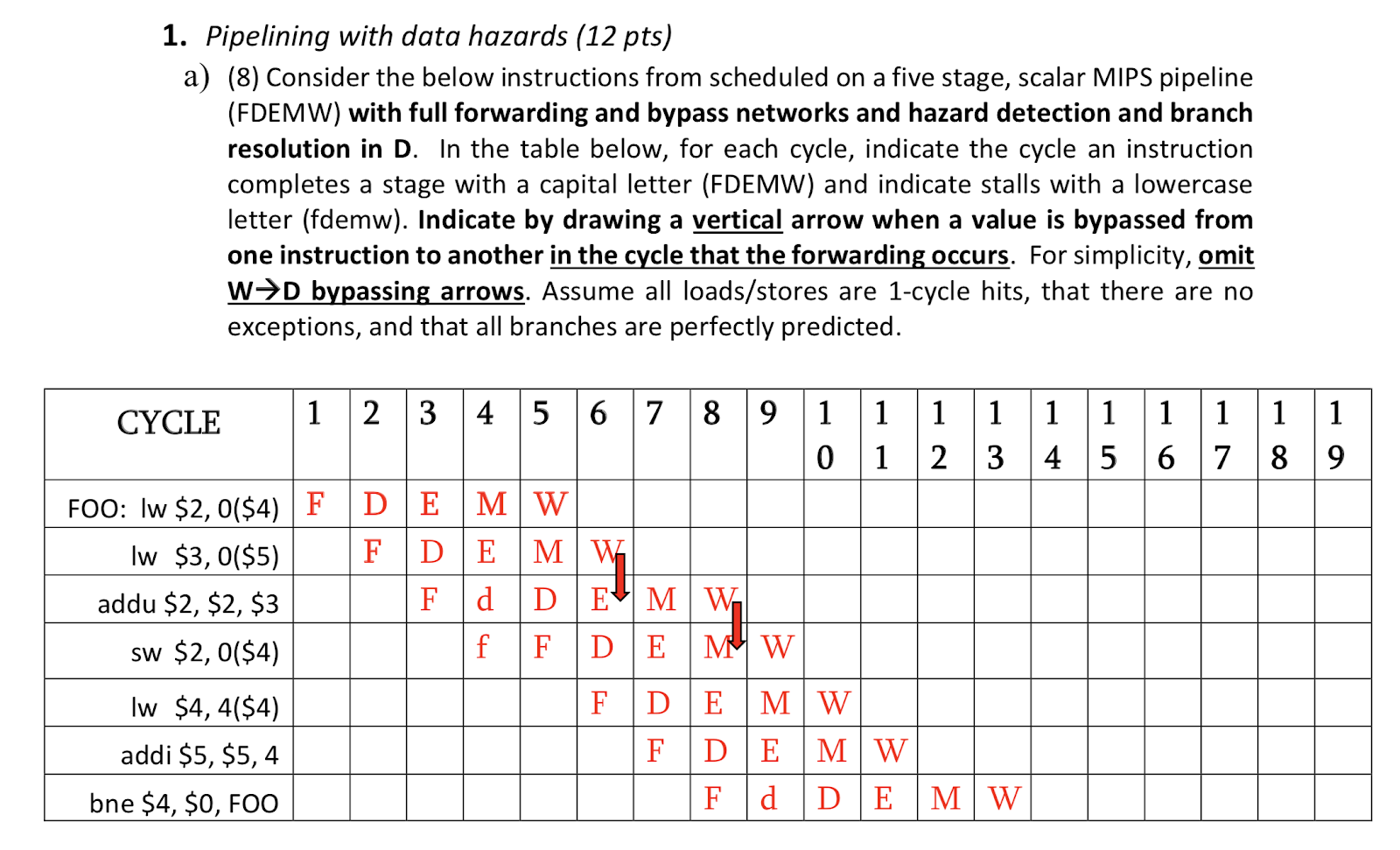

sw는 Execute에서 일어나나 보네
Branch Execution도 E에 일어나고 이게 Bracnh Resolution
'PSU > CSE 530 - Computer Architecture' 카테고리의 다른 글
| [CSE 530] Midterm - 1 (1) | 2019.10.09 |
|---|---|
| [CSE 530] - Quiz (0) | 2019.10.09 |
| [CSE 530] - Computer Architecture problems (0) | 2019.10.05 |
| The evolution of RISC technology at IBM - 논문 공부 (0) | 2019.09.08 |

