
목록Cloud Computing/NLP (9)
MJay
NLP 인간이 쓰는 언어 현상을 기계적으로 분석해서 컴퓨터가 이해할 수 있는 형태로 만드는 자연 언어 이해 혹은 그러한 형태를 다시 인간이 이해할 수 있는 언어로 표현하는 기술이다. Text Mining 비정형 데이터 마이닝의 방법이다. 비정형 데이터를 문서 처리기술과 자연어 처리 기술을 사용하여 유용한 정보를 추출하고 가공하는 기술이다. Machine Learning 인공 지능의 한 분야로 컴퓨터가 학습할 수 있도록 알고리즘과 기술을 개발하는 분야이다. NLP에서 쓰이는 ML은 kNN, Naive Bayes, SVM, CRF++ , Neural Network, HMM, MEMM이 있다. Deep Learning 인간의 두뇌를 모방하여 데이터를 처리하고 의사결정에 사용되는 패턴을 만드는 인공지능 기능이다..
 웹 정보 처리응용 정리해보기
웹 정보 처리응용 정리해보기
NLP 인간이 쓰는 언어 현상을 기계적으로 분석해서 컴퓨터가 이해할 수 있는 형태로 만드는 자연 언어 이해 혹은 그러한 형태를 다시 인간이 이해할 수 있는 언어로 표현하는 기술이다. Text Mining 비정형 데이터 마이닝의 방법이다. 비정형 데이터를 문서 처리기술과 자연어 처리 기술을 사용하여 유용한 정보를 추출하고 가공하는 기술이다. Machine Learning 인공 지능의 한 분야로 컴퓨터가 학습할 수 있도록 알고리즘과 기술을 개발하는 분야이다. NLP에서 쓰이는 ML은 kNN, Naive Bayes, SVM, CRF++ , Neural Network, HMM, MEMM이 있다. Deep Learning 인간의 두뇌를 모방하여 데이터를 처리하고 의사결정에 사용되는 패턴을 만드는 인공지능 기능이다..
POS Taggin lexical token Token 어휘가 있는 token POS란 품사라고 뜻한다 noun, adverbs, adjectives, pronouns, conjunction Part of Speech Tagging과 같은 뜻 tagging, labeling, annotation POS Tag Brown Corpus 문장 많이 모아 놓은것 Penn Treebank 가장 많이 쓰인다 45 Pos Tagging Claws5 “C5" taggin 종류 의미 tagging Pos tagging 구문 tagging 개체명 tagging P, L, O POS Tagsets Verbs VB,VBP,VBZ,VBD Nouns NNP,NNPS,NN,NNS POS Tagging Approaches Rule-..
데모사이트가 있다고 한다. Word2Vector - 단어를 vector로 표현 고양이를 [1,0,0,0] 개 [0,1,0,0] 사람 [0,0,1,0] 이걸로는 단어의 의미를 전혀 알 수 없으니 단어의 의미를 파악하는 벡터를 알고싶다 n-gram 어떤 단어의 출현확률은 이전 (n-1)개의 단어에 의존한다. CBOW(Original) - Continuous Bag of Word Skipgram With Center Word, we can predict context words. WordEmbedding CBOW( Continuous Bag of Word Model) Idea: Using context words, we can predict center word Probability ( “It is ( ) t..
 웹정보처리응용 2017년 4월 6일 목요일 오후 1:49
웹정보처리응용 2017년 4월 6일 목요일 오후 1:49
Python은 매우 쉽다 python packages are hierarchical modules 모듈을 수정했을 경우 reload가능 이럴경우 search앞에 re 안붙여도 된다. 여러가지 data가 있다. NLTK Annotated Text- 정보가 달려있는 text (e.g 품사) 품사를 결정해주는게 Part Of Speech Tagging이다. token은 단어를 만들어주는 것이다. 단어의 위치에 따라서도 불러낼수있다 blank space regular expression over ova gaeova gae ssip ova
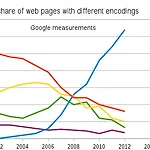 EUC-KR , Unicode, UTF-8, UTF-8에 대해서
EUC-KR , Unicode, UTF-8, UTF-8에 대해서
EUC-KR = KS완성형 + ASCII ASCII 는 1 Byte이다. Window는 EUC-KR을 쓴다 윈도우에서 txt 파일은 EUC-KR이지만 ppt 파일이나 excel 파일은 unicode로 바뀐다고 한다 Linux는 UTF-8을 쓴다 Unicode라고 생각하자 한글을 초성 19개 중성 21개 종성 27개이다 C/C++ 은 KS완성형이였다 자바부터 Java, Python, Ruby부터 Unicode가 나왔다.
 Applied Natural Language Processing - 3주차
Applied Natural Language Processing - 3주차
Applied Natural Language Processing Feature Selection TI.IDF Term weighting Term Normalization에 대해서 알아보자 Text를 Categorize할때 신경써야 할 부분이 있다. 일단 언어적인 표현이다. Words 도 대문자가 있고 소문자가 있기 때문에 신경써줘야하고 또한 복수 texts 같은 건 text로 바꾸면 된다. Word-level n-grams 은 뭘까 간단하게 말해서 입력한 문자열을 N개의 기준 단위로 절단하는 방법이다. 나누는 기준은 한 글자가 될수 있고 단어가 될 수 있다. 이 외등등 구두법도 따져야한다. beside there are another things to consider. non-linguistic feat..
 웹 정보 처리 응용 (2주차)
웹 정보 처리 응용 (2주차)
AI, Machine Learning, Deep Learning에 대해서 알아보자 AI 는 지식표현, game therory, NLP, Q&A 등등이 들어있따 Machine Learning은 알고리즘이고 Deep Learning은 이렇게 3가지가 유명하다 AI는 대표적인 예는 NLP로 성공한 Apple의 시리이다 Deep Learning의 대표적인 예는 AlphaGo 요즘은 인간보다 로봇이 글을 더 잘 쓴다고 한다. 날씨도 로봇이 더 잘한다고 한다. python으로도 이렇게 nlp을 지원해주는 tool이 있다.
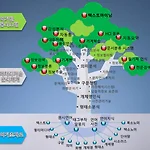 1주차 웹 정보 처리와 응용
1주차 웹 정보 처리와 응용
1주차라서 짧게 설명하셨다. 4차 혁명의 핵심은 AI 와 BigData 와 Machine Learning이다. 자연어 처리도 빅 데이터 분석이랑 머신러닝 기법 을 쓴다. -> 자연어 처리 아래서부터 보면 국어기초자료가 있다. 보면 언어사전 태그부착 말뭉치, 형태소분석 등등 거의 기초자료가 많다. 위로 올라가면 국어처리기술 및 관리체계가 있다. 형태소 분석을 하고 개체명 인식을 한다. 개체명 인식이란 Name Identity 를 뜻한다 예로 들면 Obama, Trump이 있다. 개체명이 장소인지 이름인지도 인식하는게 개체명 인식이다. 예로 들면 KookMin(Location , Name) 이 2가지 의미가 있을 수 있는데 국민대에서 밥을 먹었다는 건 장소를 뜻하고 국민대학교의 위치는 국민대학교 라는 이름을..